Recurrent Neural Network
Introduction
Standard network works well usually, however, it still have some problems.
Though we can include as many hidden layers as we want in the standard neural network, the input and output can only be the same length. That is not quite useful in application, since you cannot translate "I like Natural Language Processing a lot!" to "我爱自然语言处理很多!", which sounds really wierd.
The other problem is it doesn't share features learned across different positions of text. Like the sentence "Cali and Wenjing are good friends." If we got a sign that "Cali" is a name, we want the the network autometically considers "Wenjing" is another person's name.
The basic idea of RNN is showed in the graph below.
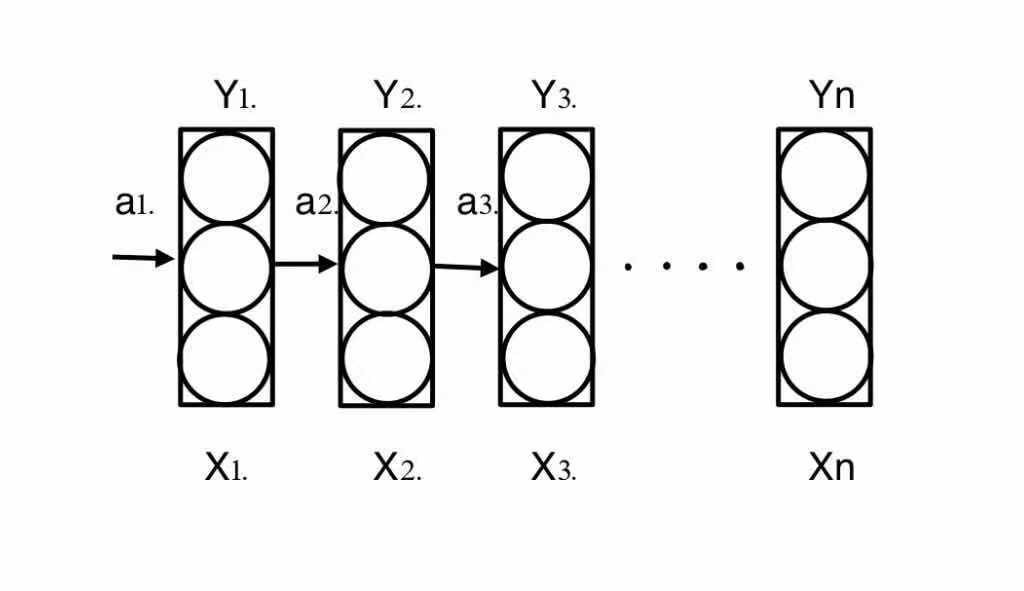
Many-to-one Case
However, one of the advantange of RNN is it can make the output differs from the input. Many-to-one can give us a good intuition. One application of many-to-one case is the sentiment classification, when input is a sentence, that means n words(N = n), and output is a score between 1 - 5.
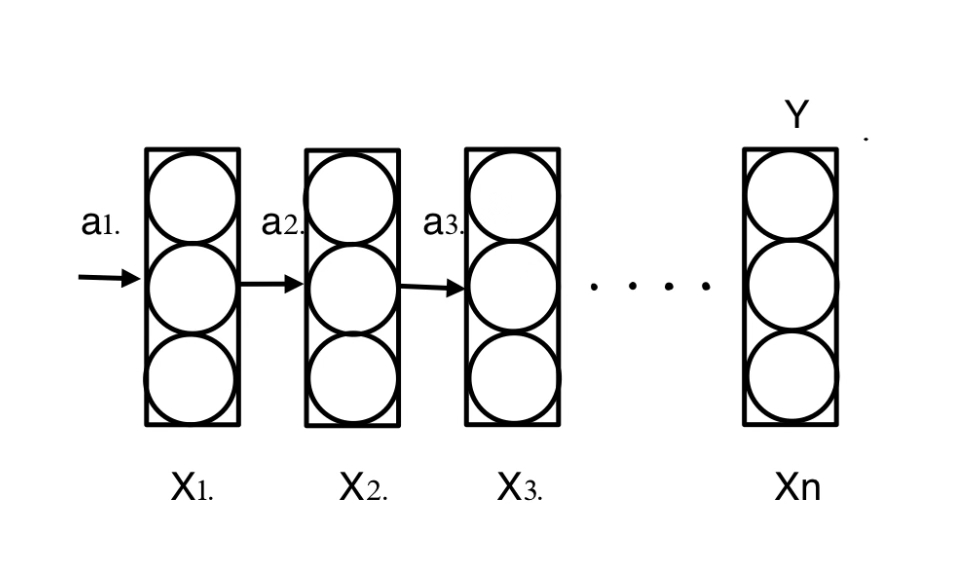
One-to-many Case
One-to-many case is almost the same. It usually works in the music generation. You can input a single integer, or even a NULL.
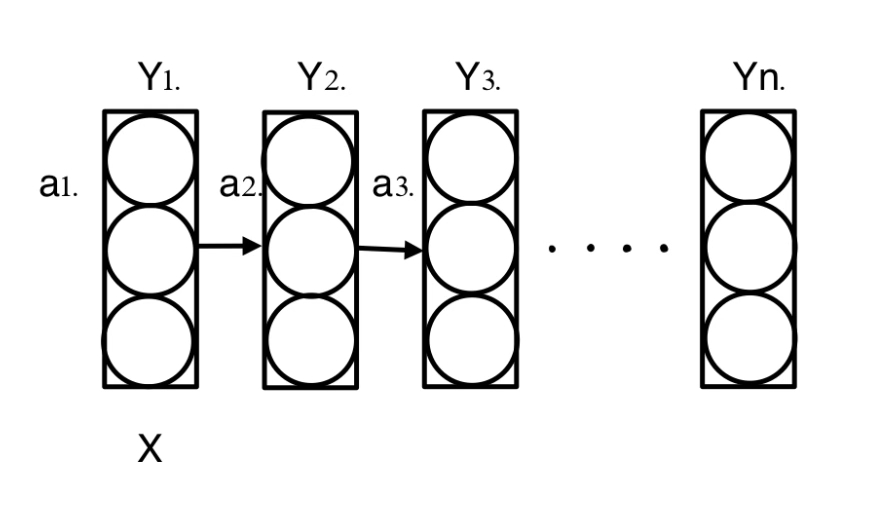
Many-to-many Case
Intuition
Many-to-many case can also be fancy. In the pragh below, we can actually divide the RNN into two parts. The first part is the encode part, where we input X and output nothing; the second part is the decode part, where, in contrast, we only output Y.
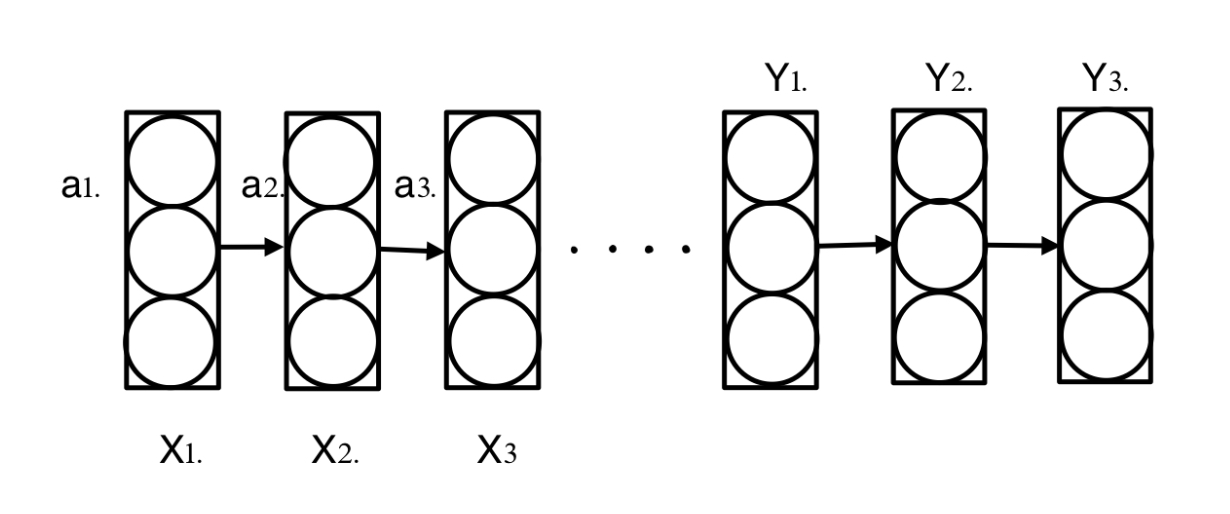
Application - Machine Translation
(English)Input: x = "I like Natural Language Processing a lot!"
(Chinese)Output: y = "我非常喜欢自然语言处理!"
The result above is from Google Translate(https://translate.google.com/)
Conclusion
Input X is the vector of x_i, i = 1...N. y_i is effected not only by x_2, but also by y_1...y_(i-1). RNN is quite useful in machine translation, word prediction, sentiment classification and name entity recognition.
Application: Sentence Representation
Word Representation
The basic idea is to define a dictionary(or sometimes people call this vocabulary) first. The dictionary contains all the words you might be interested in. Usually we can choose the public corpus like STS and SSTB.
And then tokenize is one of the most important step. The tokenize in RNN is similar to the tokenize method in the standard network. Since the vacabulary is relatively large, usually above 50k, we need to use sparse matrix to represent it.
After that, we need to train the model over some text files and start to play around!
Character Representation
The intuition of the character model is similar. The only difference due to the input X. In the character model, we consider single letter as an input. The advantage of this model compared with the previous one is that it can deal with unknown words more smoothly, though it is relatively expensive to compute. With the high-performance of modern computer, the character model has become more and more popular.
Adjustification
Vanishing Gradients
The basic idea of the computation of RNN is the same with standard network, using forward-propogation and back-propogation. RNN is mainly local influence, meaning that the value of Ym is mainly influenced by values Xi close to Ym. We always call this vanishing gradients. Vanishing gradients makes RNN a network not quite useful in long depending sentence. This is one of the RNN's drawbacks.
GRU
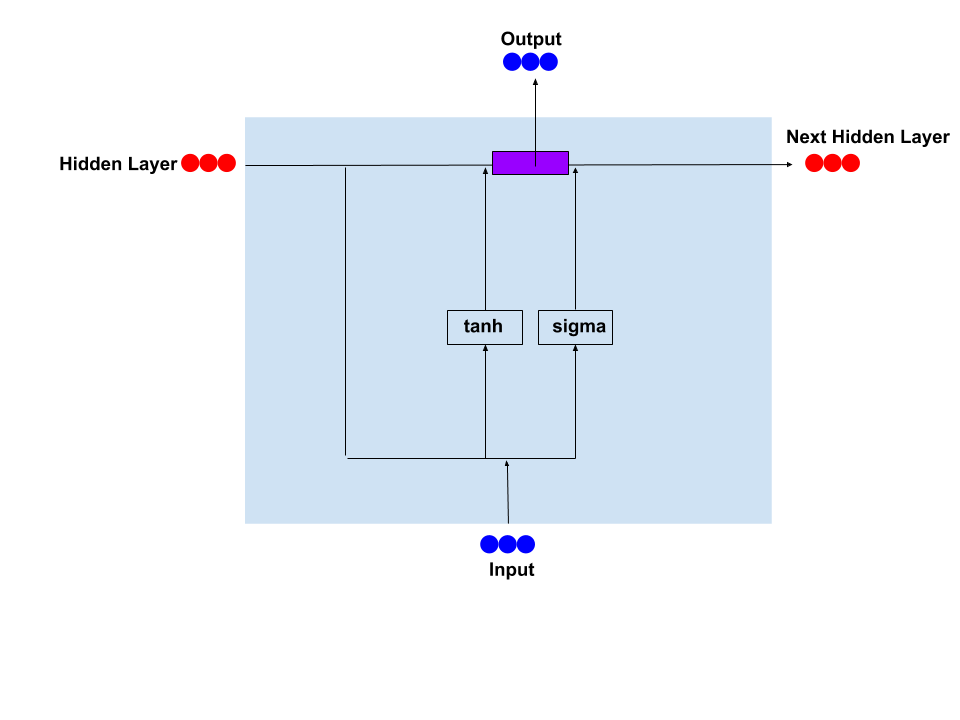
The basic thought of GRU is using update function Γ as a signal. For example, in sentence "The girl with superpower ...(omit relatively long matrial) is working". In standard RNN, since the sentence is long, the influence of "girl" to the word "has" is quite small and we can unsider it 0 if the sentence is long enough. However, in GRU model, the function Γ(u) equals to 0 until the model meet the word "girl", the function Γ(u) get a new value 1, that is called update the Γ to 1. Though the sentence is long, the value of Γ won't change until it meet another word "has".
The Γ function is just like a signal, using small memory to store the information of very long dependency.
LSTM
Similar to GRU, the main difference is LSTM has 3 gates(update gate, forget gate and output gate) while GRU has 2 gates(update gate and output gate) as shown above. LSTM is much more complicated than GRU, since it requires more computation.
Model in Python
This notes is based on Keras.
from keras.prepocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import Embedding, LSTM
import numpy as np
embedding_length = 5
max_doc = 10
encoded = pad_sequences(encoded_doc, truncating = "post", padding = "post", maxlen = max_doc)
Then create the model.
model = Sequential()
model.add(Embedding(vocab_size, embedding_size, input_length = max_doc))
model.add(LSTM(units=64))
model.compile("rmsprop", "mse")
model.summary()
output = model.predict(encoded_doc)
print(output)
BRNN
RNN works pretty well in general cases. However, this model is not perfect. The main problem of RNN is it cannot use future information. Like when you compute the 2nd output, you cannot take inputs later than 2nd into account. In order to getting information from the future, we can use BRNN(Bidirectional RNN).
Adding forward activation and backward activation together, BRNN uses past information and future information, making the model become more and more popular.
Continue reading...